library(tidyverse)
penguins |>
mutate(nice_label = paste0(
species, " (", sex, "; weight: ", body_mass,
" g; flipper length: ", flipper_len, " mm)"
)) |>
select(nice_label) |>
head(4)
## nice_label
## 1 Adelie (male; weight: 3750 g; flipper length: 181 mm)
## 2 Adelie (female; weight: 3800 g; flipper length: 186 mm)
## 3 Adelie (female; weight: 3250 g; flipper length: 195 mm)
## 4 Adelie (NA; weight: NA g; flipper length: NA mm)Week 8 FAQs
FAQs
Using paste0() to build complex text is annoying! Is there a better way?
In the example, I use paste0() to build text. The paste() function takes text and variables and concatenates them together into one string or character variable.
For instance, if I want to take the penguins data and make a column that says something like Species (sex; weight: X g; flipper length: Y mm), I’d do this:
That works, but that mix of variable names and quoted things inside paste0() is horrendously gross and hard to read and annoying to type!
Fortunately there’s a better way! The {glue} package (which is installed as part of the tidyverse, but not loaded with library(tidyverse)) lets you substitute variable values directly in text without needing to separate everything with commas. Anything inside curly braces {} will get replaced with the value in the data:
library(glue)
penguins |>
mutate(nice_label = glue(
"{species} ({sex}; weight: {body_mass} g; flipper length: {flipper_len} mm)"
)) |>
select(nice_label) |>
head(4)
## nice_label
## 1 Adelie (male; weight: 3750 g; flipper length: 181 mm)
## 2 Adelie (female; weight: 3800 g; flipper length: 186 mm)
## 3 Adelie (female; weight: 3250 g; flipper length: 195 mm)
## 4 Adelie (NA; weight: NA g; flipper length: NA mm)Much nicer!
Why did we use free y-axis scales? Wouldn’t it be better to keep them the same across panels?
Sure! Either way is fine—it just depends on the story you’re trying to tell. If you want to see the shape of the trend within each state, having free scales is helpful. If you want to compare trends across states, using fixed scales is better.
I tried to resize my small multiples plot and it didn’t work—why?
I saw two common issues for why small multiples plots didn’t resize correctly:
- You used
fig.widthorfig_widthorfigwidthinstead offig-width. You have to usefix-widthandfig-height(with a-dash) - You included other content earlier in the chunk. Remember from this that chunk options must be the first things inside a chunk.
Why did my slopegraph labels repeat on both sides?
When making your slopegraph, lots of you used two geom_text() (or geom_text_repel()) layers with different hjust arguments to make the labels left- and right-aligned, but you ended up with this:
library(gapminder)
library(ggrepel)
example_slope_graph <- gapminder |>
filter(year %in% c(1977, 2007), continent != "Oceania") |>
group_by(year, continent) |>
summarize(avg_lifeExp = mean(lifeExp))
ggplot(
example_slope_graph,
aes(x = factor(year), y = avg_lifeExp, color = continent, group = continent)
) +
geom_line() +
geom_text(aes(label = continent), hjust = 0) +
geom_text(aes(label = continent), hjust = 1) +
guides(color = "none") +
labs(x = NULL, y = "Average life expectancy") +
theme_minimal()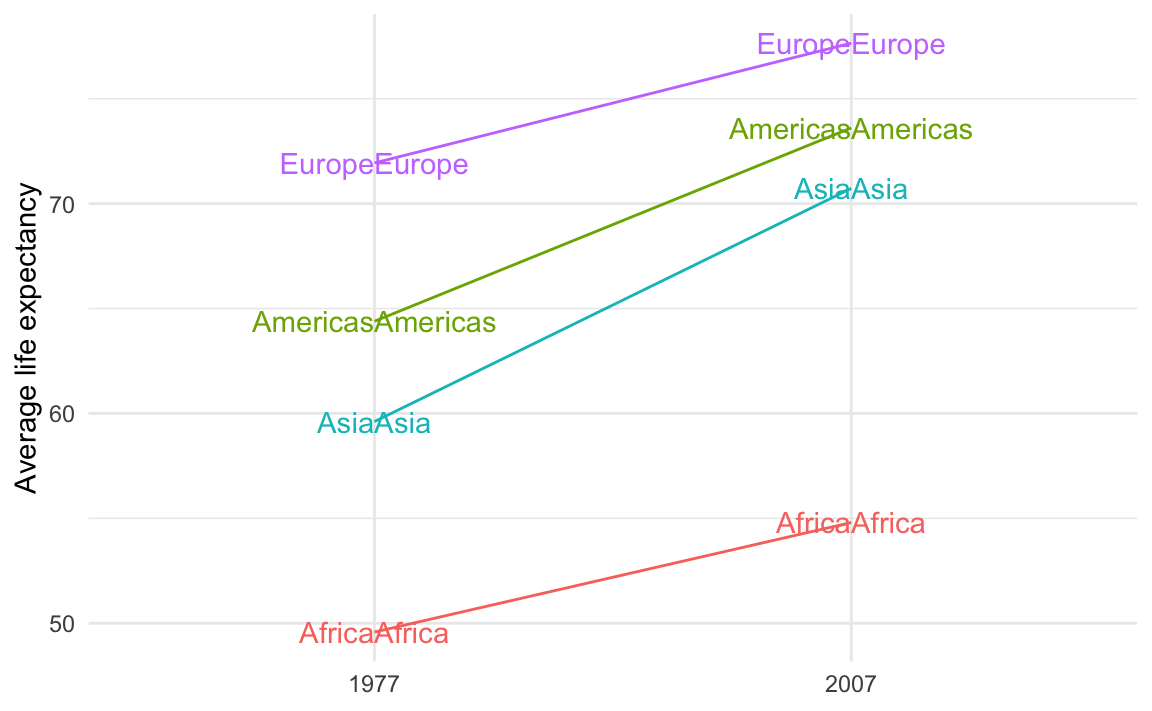
That’s because you’re plotting the values twice. You should plot them twice, but you need to control which ones you’re plotting. You want the labels for the left side of the plot (1977 here) to be right-aligned and the labels for the right side of the plot (2007 here) to be left-aligned.
To do that, you can filter the data that you’re plotting with each of the geom_text() layers:
ggplot(
example_slope_graph,
aes(x = factor(year), y = avg_lifeExp, color = continent, group = continent)
) +
geom_line() +
geom_text(
data = filter(example_slope_graph, year == 2007),
aes(label = continent),
hjust = 0
) +
geom_text(
data = filter(example_slope_graph, year == 1977),
aes(label = continent),
hjust = 1
) +
guides(color = "none") +
labs(x = NULL, y = "Average life expectancy") +
theme_minimal()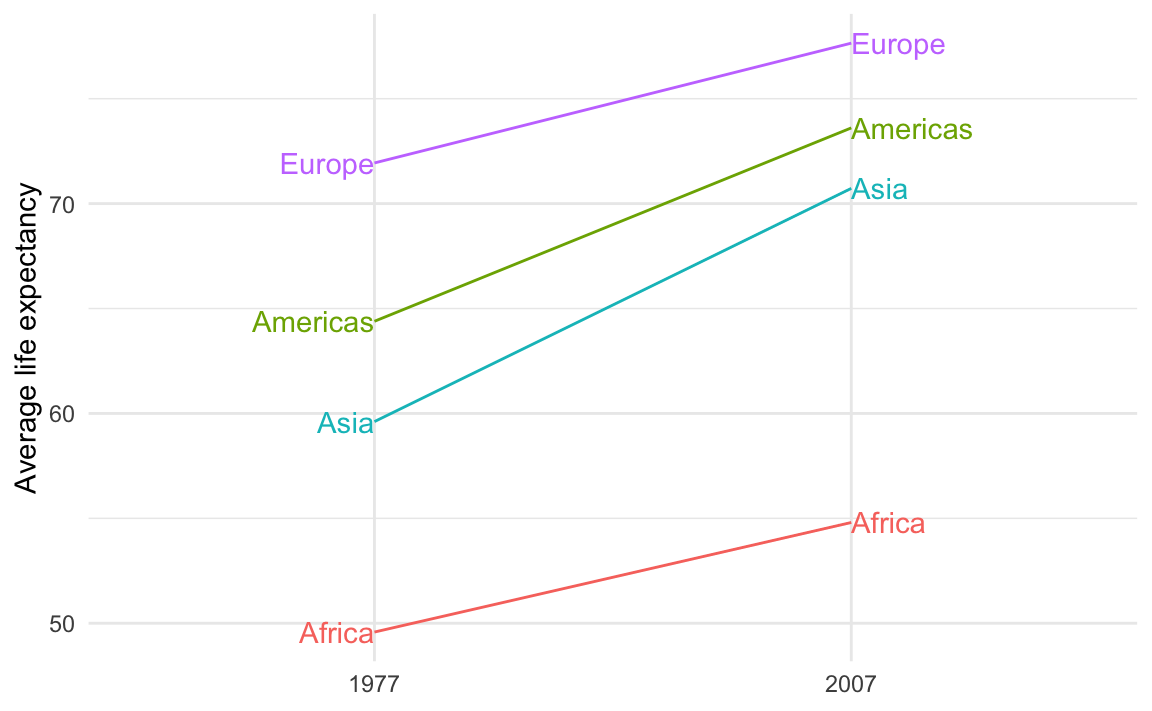
Alternatively, you can avoid filtering and instead make two different columns—one with labels for the first/left side and one with labels for the last/right side. This is what I do in the example. This is especially useful if you’re customizing the labels so that the first is formatted differently from the last.
For instance, we can use the continent name and life expectancy for the first label and just the life expectancy for the last label, since there’s no need to repeat the continent name. We’ll use glue() from the {glue} package to make two label columns. The first version is only present in 1977; the second version is only present in 2007:
library(glue)
example_slope_graph_nice_labels <- gapminder |>
filter(year %in% c(1977, 2007), continent != "Oceania") |>
group_by(year, continent) |>
summarize(avg_lifeExp = mean(lifeExp)) |>
mutate(
label_first = ifelse(
year == 1977,
glue("{continent}:\n{round(avg_lifeExp, 2)} years"),
NA
),
label_last = ifelse(
year == 2007,
glue("{round(avg_lifeExp, 2)} years"),
NA
)
)
example_slope_graph_nice_labels
## # A tibble: 8 × 5
## # Groups: year [2]
## year continent avg_lifeExp label_first label_last
## <int> <fct> <dbl> <chr> <chr>
## 1 1977 Africa 49.6 "Africa:\n49.58 years" <NA>
## 2 1977 Americas 64.4 "Americas:\n64.39 years" <NA>
## 3 1977 Asia 59.6 "Asia:\n59.61 years" <NA>
## 4 1977 Europe 71.9 "Europe:\n71.94 years" <NA>
## 5 2007 Africa 54.8 <NA> 54.81 years
## 6 2007 Americas 73.6 <NA> 73.61 years
## 7 2007 Asia 70.7 <NA> 70.73 years
## 8 2007 Europe 77.6 <NA> 77.65 yearsNow we can use those two label columns and we don’t need to filter anymore:
ggplot(
example_slope_graph_nice_labels,
aes(x = factor(year), y = avg_lifeExp, color = continent, group = continent)
) +
geom_line() +
geom_text(aes(label = label_first), hjust = 1) +
geom_text(aes(label = label_last), hjust = 0) +
guides(color = "none") +
labs(x = NULL, y = "Average life expectancy") +
theme_minimal()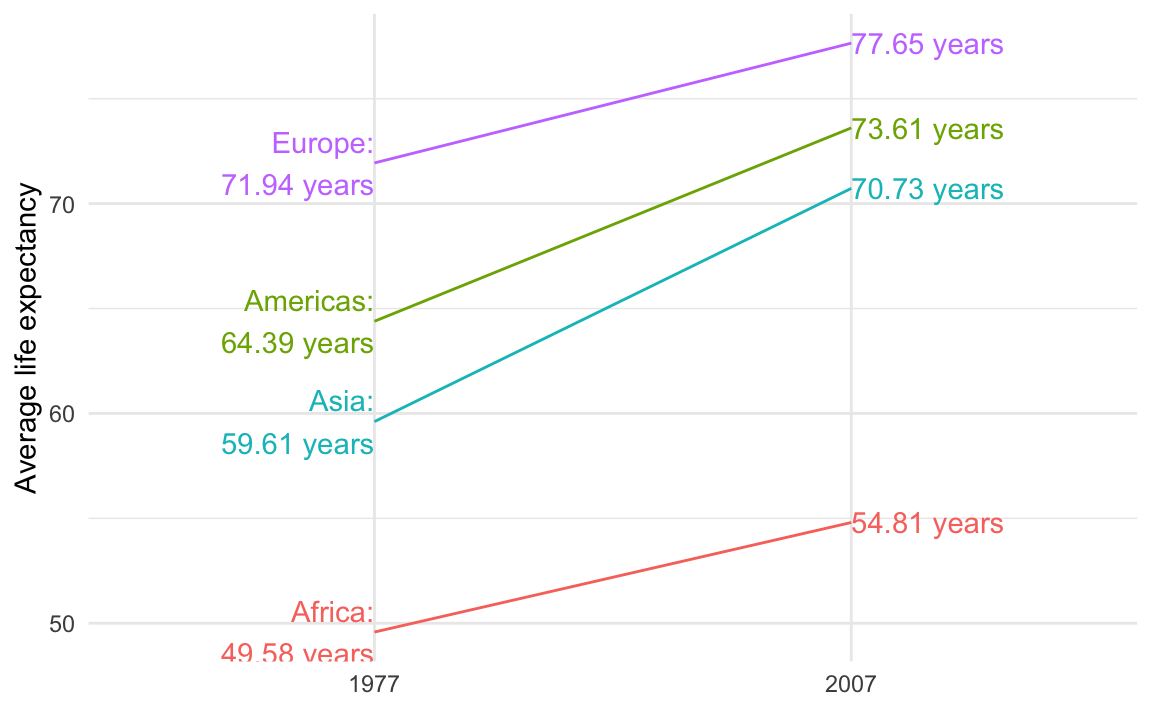
The guide lines in the slopegraph look like real lines of data! Is there a way to fix that?
If you’re using {ggrepel} the repelled labels will have little guide lines to indicate the points they’re supposed to represent:
ggplot(
example_slope_graph,
aes(x = factor(year), y = avg_lifeExp, color = continent, group = continent)
) +
geom_line() +
geom_text_repel(
data = filter(example_slope_graph, year == 2007),
aes(label = continent),
hjust = 0,
direction = "y",
nudge_x = 0.5,
seed = 1234
) +
geom_text_repel(
data = filter(example_slope_graph, year == 1977),
aes(label = continent),
hjust = 1,
direction = "y",
nudge_x = -0.5,
seed = 1234,
) +
guides(color = "none") +
labs(x = NULL, y = "Average life expectancy") +
theme_minimal()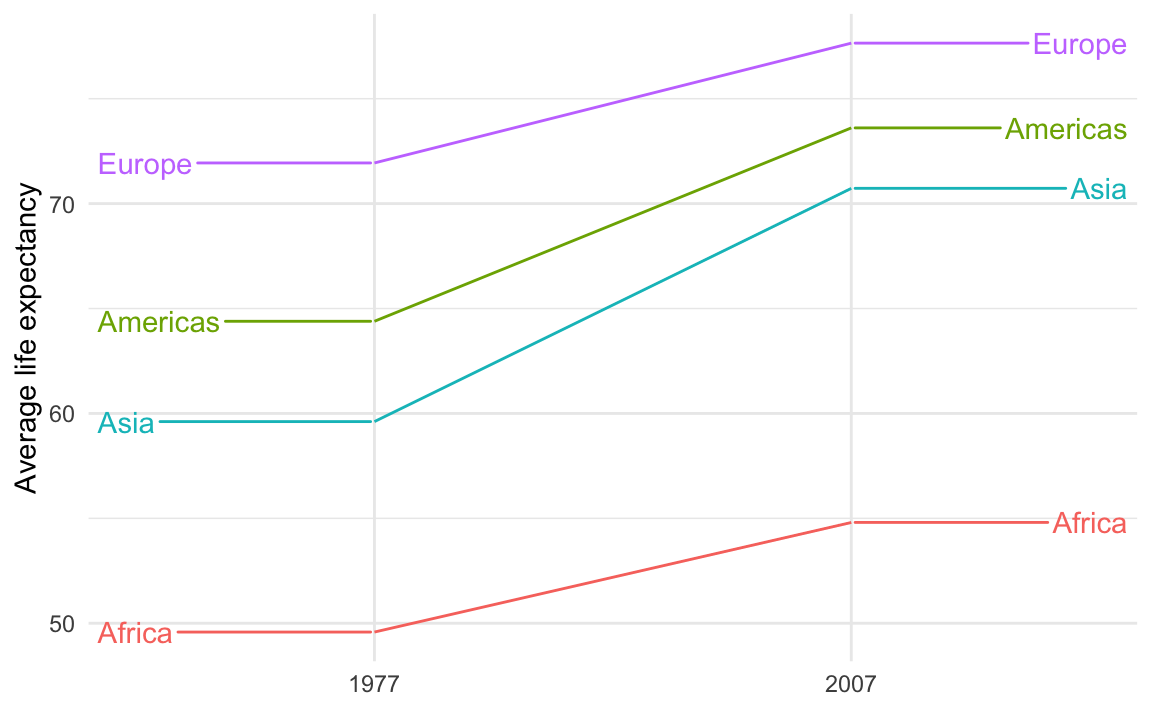
Those guide lines are helpful, but they look too much like actual data lines! It looks like life expectancy goes flat for the years before 1977 and after 2007.
This is breaking the C in CRAP—there’s not a lot of contrast between the data lines and the guide lines.
To fix it, make them different and add contrast. For instance, we can make the data lines thicker with linewidth and make the guide lines dotted with segment.linetype:
ggplot(
example_slope_graph,
aes(x = factor(year), y = avg_lifeExp, color = continent, group = continent)
) +
geom_line(linewidth = 1.5) +
geom_text_repel(
data = filter(example_slope_graph, year == 2007),
aes(label = continent),
hjust = 0,
direction = "y",
nudge_x = 0.5,
seed = 1234,
segment.linetype = "dotted"
) +
geom_text_repel(
data = filter(example_slope_graph, year == 1977),
aes(label = continent),
hjust = 1,
direction = "y",
nudge_x = -0.5,
seed = 1234,
segment.linetype = "dotted"
) +
guides(color = "none") +
labs(x = NULL, y = "Average life expectancy") +
theme_minimal()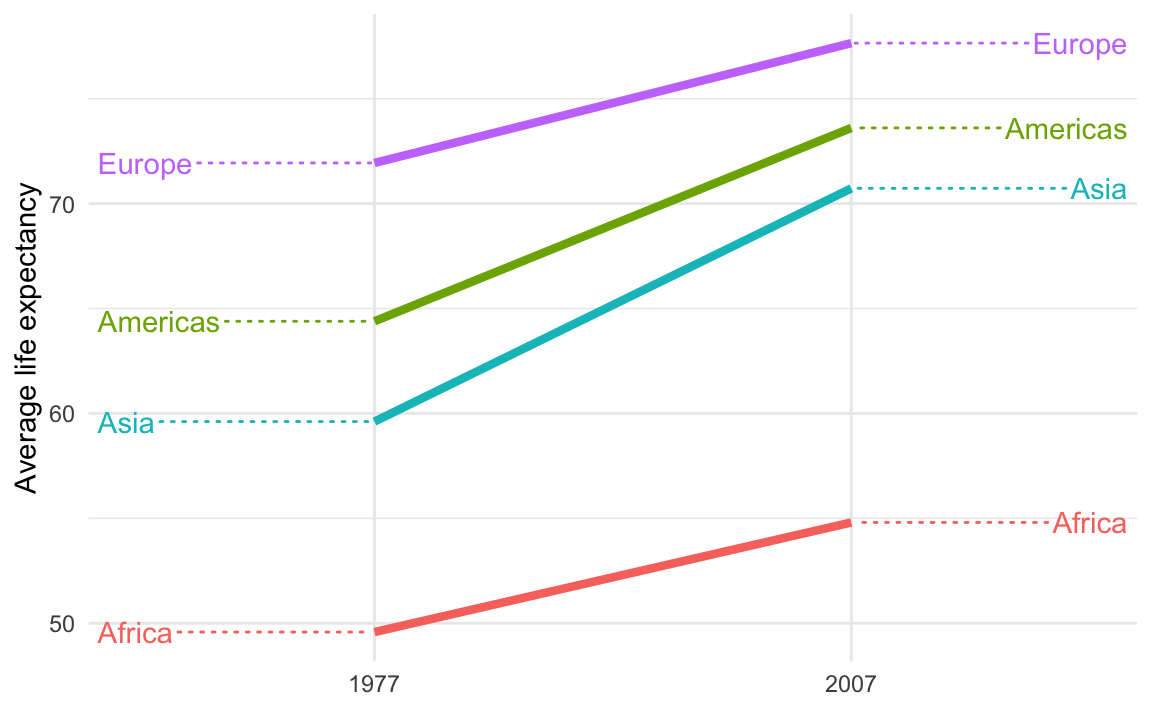
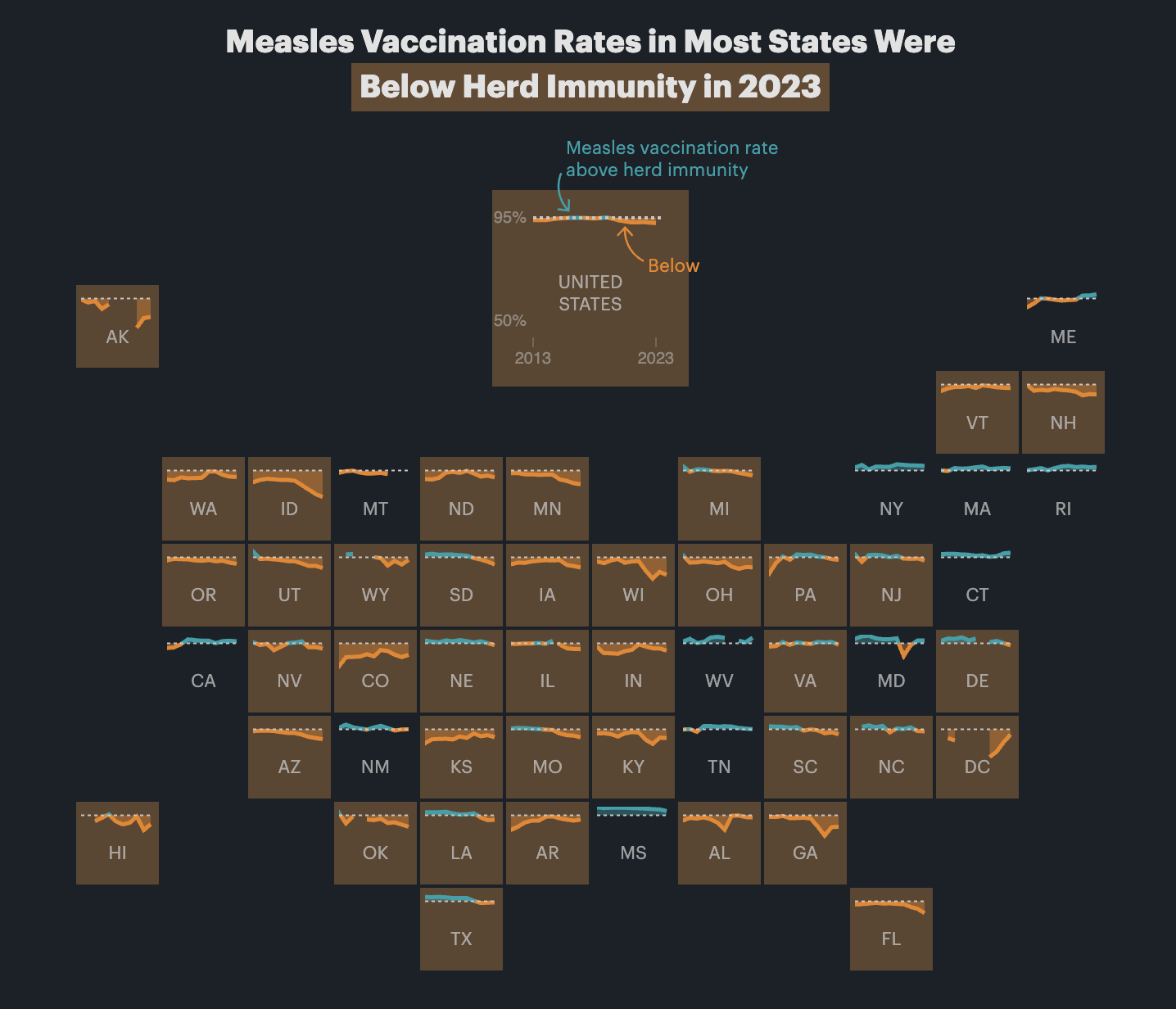
Are geofacet plots used in real life?
Yes! You’ll see them pop up all over the place. Check out this article by ProPublica, for example, which includes maps like this:
How can I get month and weekday names or abbreviations for dates?
Many of you have asked how to take month numbers and change them into month names or month abbreviations.
I’ve seen some of you use something like a big if else statement: if the month number is 1, use “January”; if the month number is 2, use “February”; and so on
... |>
mutate(month_name = case_when(
month_number == 1 ~ "January",
month_number == 2 ~ "February",
month_number == 3 ~ "March",
...
))While that works, it’s kind of a brute force approach. There’s a better, far easier way!
The {lubridate} package (one of the nine packages that gets loaded when you run library(tidyverse)) has some neat functions for extracting and formatting parts of dates. You saw these in Exercise 4:
# Add columns for the year and month
mutate(
intake_year = year(intake_date),
intake_month = month(intake_date, label = TRUE, abbr = FALSE)
)These take dates and do stuff with them. For instance, let’s put today’s date in a variable named x:
x <- ymd("2025-10-21")
x
## [1] "2025-10-21"We can extract the year using year():
year(x)
## [1] 2025…or the week number using weeknum():
week(x)
## [1] 42…or the month number using month():
month(x)
## [1] 10If you look at the help page for month(), you’ll see that it has arguments for label and abbr, which will toggle text instead numbers, and full month names instead of abbreviations:
month(x, label = TRUE, abbr = TRUE)
## [1] Oct
## 12 Levels: Jan < Feb < Mar < Apr < May < Jun < Jul < Aug < Sep < ... < Dec
month(x, label = TRUE, abbr = FALSE)
## [1] October
## 12 Levels: January < February < March < April < May < June < ... < DecemberIt outputs ordred factors too, so the months are automatically in the right order for plotting!
wday() does the same thing for days of the week:
wday(x)
## [1] 3
wday(x, label = TRUE, abbr = TRUE)
## [1] Tue
## Levels: Sun < Mon < Tue < Wed < Thu < Fri < Sat
wday(x, label = TRUE, abbr = FALSE)
## [1] Tuesday
## 7 Levels: Sunday < Monday < Tuesday < Wednesday < Thursday < ... < SaturdaySo instead of doing weird data contortions to get month names or weekday names, just use month() and wday(). You can use them directly in mutate(). For example, here they are in action in a little sample dataset:
example_data <- tribble(
~event, ~date,
"Moon landing", "1969-07-20",
"WHO COVID start date", "2020-03-13"
) |>
mutate(
# Convert to an actual date
date_actual = ymd(date),
# Extract a bunch of things
year = year(date_actual),
month_num = month(date_actual),
month_abb = month(date_actual, label = TRUE, abbr = TRUE),
month_full = month(date_actual, label = TRUE, abbr = FALSE),
week_num = week(date_actual),
wday_num = wday(date_actual),
wday_abb = wday(date_actual, label = TRUE, abbr = TRUE),
wday_full = wday(date_actual, label = TRUE, abbr = FALSE)
)
example_data
## # A tibble: 2 × 11
## event date date_actual year month_num month_abb month_full week_num wday_num
## <chr> <chr> <date> <dbl> <dbl> <ord> <ord> <dbl> <dbl>
## 1 Moon… 1969… 1969-07-20 1969 7 Jul July 29 1
## 2 WHO … 2020… 2020-03-13 2020 3 Mar March 11 6
## # ℹ 2 more variables: wday_abb <ord>, wday_full <ord>Can I get these automatic month and day names in non-English languages?
Lots of you speak languages other than English. While R function names like plot() and geom_point() and so on are locked into English, the messages and warnings that R spits out can be localized into most other languages. R detects what language your computer is set to use and then tries to match it.
Functions like month() and wday() also respect your computer’s language setting and will give you months and days in whatever your computer is set to. That’s neat, but what if your computer is set to French and you want the days to be in English? Or what if your computer is set to English but you’re making a plot in German?
You can actually change R’s localization settings to get output in different languages!
If you want to see what your computer is currently set to use, run Sys.getLocale():
Sys.getlocale()
## [1] "en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8"There’s a bunch of output there—the first part (en_US.UTF-8) is the most important and tells you the language code. The code here follows a pattern and has three parts:
- A language:
en. This is the langauge, and typically uses a two-character abbreviation following the ISO 639 standard - A territory:
US. This is the country or region for that language, used mainly to specify the currency. If it’s set toen_US, it’ll use US conventions (like “$” and “color”); if it’s set toen_GBit’ll use British conventions (like “£” and “colour”). It uses a two-character abbreviation following the ISO 3166 standard. - An encoding:
UTF-8. This is how the text is actually represented and stored on the computer. This defaults to Unicode (UTF-8) here. You don’t generally need to worry about this.
For macOS and Linux (i.e. Posit Cloud), setting locale details is pretty straightforward and predictable because they both follow this pattern consistently:
en_GB: British Englishfr_FR: French in Francefr_CH: French in Switzerlandde_CH: German in Switzerlandde_DE: German in Germany
If you run locale -a in your terminal (not in your R console) on macOS or in Posit Cloud, you’ll get a list of all the different locales your computer can use. Here’s what I have on my computer:
[1] "af_ZA" "am_ET" "ar_AE" "ar_EG" "ar_JO" "ar_MA" "ar_QA" "ar_SA" "be_BY"
[10] "bg_BG" "C" "ca_AD" "ca_ES" "ca_FR" "ca_IT" "cs_CZ" "da_DK" "de_AT"
[19] "de_CH" "de_DE" "el_GR" "en_AU" "en_CA" "en_GB" "en_HK" "en_IE" "en_IN"
[28] "en_NZ" "en_PH" "en_SG" "en_US" "en_ZA" "es_AR" "es_CR" "es_ES" "es_MX"
[37] "et_EE" "eu_ES" "fa_AF" "fa_IR" "fi_FI" "fr_BE" "fr_CA" "fr_CH" "fr_FR"
[46] "ga_IE" "he_IL" "hi_IN" "hr_HR" "hu_HU" "hy_AM" "is_IS" "it_CH" "it_IT"
[55] "ja_JP" "kk_KZ" "ko_KR" "lt_LT" "lv_LV" "mn_MN" "nb_NO" "nl_BE" "nl_NL"
[64] "nn_NO" "no_NO" "pl_PL" "POSIX" "pt_BR" "pt_PT" "ro_RO" "ru_RU" "se_FI"
[73] "se_NO" "sk_SK" "sl_SI" "sr_RS" "sr_YU" "sv_FI" "sv_SE" "tr_TR" "uk_UA"
[82] "zh_CN" "zh_HK" "zh_TW"For whatever reason, Windows doesn’t use this naming convention. It uses dashes or full words instead, like en-US or american or en-CA or canadian. You can see a list here, or google Windows language country strings (that’s actually RStudio’s official recommendation for finding Windows language codes)
Once you know the language code, you can use it in R. Let’s make a little variable named x with today’s date:
x <- ymd("2024-07-12")Because I’m using English as my default locale, the output of wday() and month() will be in English:
wday(x, label = TRUE, abbr = FALSE)
## [1] Friday
## 7 Levels: Sunday < Monday < Tuesday < Wednesday < Thursday < ... < Saturday
month(x, label = TRUE, abbr = FALSE)
## [1] July
## 12 Levels: January < February < March < April < May < June < ... < DecemberThose functions have a locale argument, though, so it’s really easy to switch between languages:
wday(x, label = TRUE, abbr = FALSE, locale = "en_US")
## [1] Friday
## 7 Levels: Sunday < Monday < Tuesday < Wednesday < Thursday < ... < Saturday
wday(x, label = TRUE, abbr = FALSE, locale = "fr_FR")
## [1] vendredi
## 7 Levels: dimanche < lundi < mardi < mercredi < jeudi < ... < samedi
wday(x, label = TRUE, abbr = FALSE, locale = "fr_BE")
## [1] vendredi
## 7 Levels: dimanche < lundi < mardi < mercredi < jeudi < ... < samedi
wday(x, label = TRUE, abbr = FALSE, locale = "it_IT")
## [1] venerdì
## 7 Levels: domenica < lunedì < martedì < mercoledì < giovedì < ... < sabato
wday(x, label = TRUE, abbr = FALSE, locale = "zh_CN")
## [1] 星期五
## Levels: 星期日 < 星期一 < 星期二 < 星期三 < 星期四 < 星期五 < 星期六month(x, label = TRUE, abbr = FALSE, locale = "en_US")
## [1] July
## 12 Levels: January < February < March < April < May < June < ... < December
month(x, label = TRUE, abbr = FALSE, locale = "fr_FR")
## [1] juillet
## 12 Levels: janvier < février < mars < avril < mai < juin < juillet < ... < décembre
month(x, label = TRUE, abbr = FALSE, locale = "fr_BE")
## [1] juillet
## 12 Levels: janvier < février < mars < avril < mai < juin < juillet < ... < décembre
month(x, label = TRUE, abbr = FALSE, locale = "it_IT")
## [1] luglio
## 12 Levels: gennaio < febbraio < marzo < aprile < maggio < giugno < ... < dicembre
month(x, label = TRUE, abbr = FALSE, locale = "zh_CN")
## [1] 7月
## 12 Levels: 1月 < 2月 < 3月 < 4月 < 5月 < 6月 < 7月 < 8月 < 9月 < ... < 12月You can also set the locale for your entire R session like this:
Sys.setlocale(locale = "de_DE")
## [1] "de_DE/de_DE/de_DE/C/de_DE/en_US.UTF-8"Now month() and wday() will use German by default without needing to set the locale argument:
month(x, label = TRUE, abbr = FALSE)
## [1] Juli
## 12 Levels: Januar < Februar < März < April < Mai < Juni < Juli < ... < Dezember
wday(x, label = TRUE, abbr = FALSE)
## [1] Freitag
## 7 Levels: Sonntag < Montag < Dienstag < Mittwoch < Donnerstag < ... < SamstagI’ll switch everything back to English :)
Sys.setlocale(locale = "en_US.UTF-8")
## [1] "en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8"Seeds—why?
There were a couple common questions about seeds:
1. Why do we even need seeds?
Seeds make random things reproducible. They let you make random things again.
NoteMinecraft
If you’ve ever played Minecraft, seeds are pretty important there too. Minecraft worlds (all the mountains, oceans, biomes, mines, etc.) are completely randomly generated. When you create a new world, it gives an option to specify a seed. If you don’t, the world will just be random. If you do, the world will still be random, but it’ll be the same random. There are actually Reddit forums where people play around with different seeds to find interesting random worlds—like weirdly shaped landmasses, interesting starting places, and so on. Some gamers will stream their games on YouTube or Twitch and will share their world’s seed so that others can play in the same auto-generated world. That doesn’t mean that others play with them—it means that others will have mountains and trees and oceans and mines and resources in exactly the same spot as them, since it’s the same randomly auto-generated world.
When R (or any computer program, really) generates random numbers, it uses an algorithm to simulate randomness. This algorithm always starts with an initial number, or seed. Typically it will use something like the current number of milliseconds since some date, so that every time you generate random numbers they’ll be different. Look at this, for instance:
# Choose 3 numbers between 1 and 10
sample(1:10, 3)
## [1] 9 4 7# Choose 3 numbers between 1 and 10
sample(1:10, 3)
## [1] 5 6 9They’re different both times.
That’s ordinarily totally fine, but if you care about reproducibility (like having a synthetic dataset with the same random values, or having jittered points in a plot be in the same position every time you render), it’s a good idea to set your own seed. This ensures that the random numbers you generate are the same every time you generate them.
If you set a seed, you control how the random algorithm starts. You’ll still generate random numbers, but they’ll be the same randomness every time, on anyone’s computer. Run this on your computer:
set.seed(1234)
sample(1:10, 3)
## [1] 10 6 5You’ll get 10, 6, and 5, just like I did here. They’re random, but they’re reproducibly random.
In data visualization, this is especially important for anything with randomness, like jittering points or repelling labels.
For instance, if we make this jittered strip plot of penguin data:
penguins <- palmerpenguins::penguins |> drop_na(sex)
ggplot(penguins, aes(x = species, y = body_mass_g)) +
# height = 0 makes it so points don't jitter up and down
geom_point(position = position_jitter(width = 0.25, height = 0))
That looks cool. But if we rerender it:
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_point(position = position_jitter(width = 0.25, height = 0))
…it’s slightly different. And if we do it again:
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_point(position = position_jitter(width = 0.25, height = 0))
…it’s different again! It’s going to be different every time, which is annoying.
Slight variations in jittered points is a minor annoyance—a major annoyance is when you tinker with settings in geom_label_repel() to make sure everything is nice and not overlapping, and then when you render the plot again, everything is in a completely different spot. This happens because the repelling is random, just like jittering. You want the randomness, but you want the randomness to be the same every time.
To ensure that the randomness is the same each time, you can set a seed. position_jitter() and geom_label_repel() both have seed arguments that you can use. Here’s a randomly jittered plot:
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_point(position = position_jitter(width = 0.25, height = 0, seed = 1234))
And here’s that same plot jittered again, but with the same randomness—it’s identical!
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_point(position = position_jitter(width = 0.25, height = 0, seed = 1234))
You can also use set.seed() separately outside of the function, which sets the seed for all random things in the document (though note that this doesn’t create the same plot that position_jitter(seed = 1234) does! There are technical reasons for this, but you don’t need to worry about that.)
set.seed(1234)
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_point(position = position_jitter(width = 0.25, height = 0))
2. How should we choose seeds?
What should you use a seed? Whatever you want, really. In the slides, I had these as examples:
- Quick ones:
1234(567)1
- Goofy/nerdy ones:
13(common (un)lucky number)42(the answer to life, the universe, and everything)8675309(Jenny’s number)24601(Jean Valjean’s inmate number in Les Misérables)
- Practical ones:
- The date of the analysis, like
20250715for something written on July 15, 2025 - A truly random integer based on atmospheric noise from RANDOM.ORG
- The date of the analysis, like
In practice, especially for plots and making sure jittered and repelled things look good and consistent, it doesn’t really matter what you use.
Here’s what I typically do:
- For plotting things, I’ll generally just use 1234. If I’m not happy with the shuffling (like two labels are too close, or one point is jittered too far up or something), I’ll change it to 12345 or 123456 or 123 until it looks okay.
- For analysis, I’ll generate some 6- or 7-digit integer at RANDOM.ORG and use that as the seed (I do this all the time! Check out this search of my GitHub repositories). This is especially important in things like Bayesian regression, which uses random simulations to calculate derivatives and do all sorts of mathy things. Seeds are crucial there for getting the same results every time.